xAPI & Valamis LRS – Fünf Jahre in der Produktion: Was wir gelernt haben
2014 haben wir unser eigenes LRS implementiert und begonnen, unsere ersten xAPI-Anweisungen zu erstellen. Was haben wir auf dieser Reise bisher gelernt?


Die Ursprünge von Experience API (oder xAPI) gehen auf das Jahr 2010 zurück, als ADL ein Forschungsprojekt, das Tin Can Project, initiierte, das von Rustici Software durchgeführt wurde. Dieses Projekt führte zur Tin Can API-Spezifikation, die später zur xAPI-Spezifikation wurde. Die Version 1.0.0.0 der xAPI wurde am 27. April 2013 freigegeben.
Es gab viel Interesse und Begeisterung auf dem Markt für diese neuen Technologien, und wir waren nicht anders. Das Produktentwicklungsteam von Valamis verfolgte die Entwicklung von xAPI genau, und 2014 implementierten wir unseren eigenen Learning Record Store (LRS) und begannen mit der Erstellung unserer ersten xAPI-Anweisungen, um die Fortschritte der Lernenden auf unserer Learning Experience Platform (LXP) zu dokumentieren.
Von Tausenden bis zu Millionen von erfassten Statements
Lassen Sie mich zunächst die zentralen Begriffe klären, die in diesem Blog verwendet werden. xAPI ist ein Standard (oder eine Spezifikation), der das Verfolgen, Speichern und Teilen der Lernerfahrung des Benutzers über Plattformen und in mehreren Kontexten hinweg ermöglicht. Ein Learning Record Store (LRS) ist ein Datenspeichersystem, das als Speicher für Lernaufzeichnungen dient, die von angeschlossenen Systemen gesammelt werden.
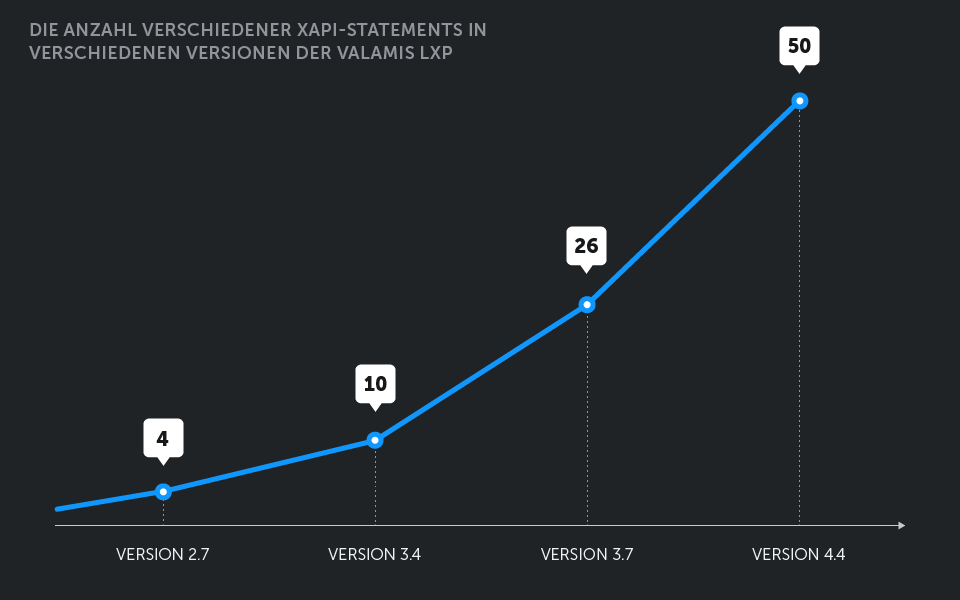
Die Produktion von Valamis LRS begann im Herbst 2014 – seitdem hat sich viel verändert, und wir haben auch viel gelernt. Die Anzahl der verschiedenen Ereignisse, die von xAPI-Anweisungen in Valamis LXP erfasst werden, hat sich mehr als verzehnfacht, von nur 4 anfänglich auf 50 in der neuesten Version, wobei mit jedem neuen Release mehr Ereignisse hinzukommen. Die tägliche Erzeugungsrate für einige der Umgebungen unserer Kunden (siehe Bild unten) liegt bei Zehntausenden von Statements, wobei die jüngste Spitzenleistung von zwei Millionen an nur zwei Tagen erfasst wurde. Diese drastisch steigenden Zahlen sind ein positives Zeichen, aber dahinter standen viel Schweiß und Tränen, lange Tage und eine erhebliche Teamleistung.
Daten — Jede Menge Daten
Die erste und wichtigste Lektion für uns war, dass unser LRS nicht einfach nur Daten enthalten würde – es würde einen riesigen, unverständlichen Haufen davon enthalten. Von Anfang an standen wir vor der Frage, wie wir aus den gesammelten Daten einen Sinn extrahieren können. Bald wurde uns klar, dass xAPI nicht wirklich für das Reporting konzipiert war und dass unser naiver Ansatz, Berichte durch eine direkte Abfrage vom LRS zu erstellen, nicht die klügste Wahl war.
In den letzten Jahren haben wir viele iterative Verbesserungen vorgenommen, um xAPI-Anweisungen spontan verarbeiten und Echtzeitanalysen basierend auf den gesammelten Daten präsentieren zu können, aber wir sind mit dem aktuellen Stand noch lange nicht zufrieden. Deshalb arbeiten wir an einer NoSQL-Lösung, die uns die Möglichkeit gibt, mit Hilfe von Spark Echtzeitanalysen durchzuführen.
Herausforderungen bei der Migration
Eine weitere Implikation der Datenmenge ist neben der Analyseleistung die Schwierigkeit der iterativen Evolution, nämlich die Migration. Jede Verbesserung des Datenmodells und der Speicherung erfordert die Migration vorhandener Daten in das neue Modell, und unser naiver Ansatz, diese Datenbankmigrationen durchzuführen, führte direkt zu langen (und meist unerwarteten) Wartungspausen.
Wir mussten unseren gesamten Ansatz für die Migration überdenken, und schließlich haben wir eine einfache Lösung gefunden – anstatt die Migration für das Live-LRS durchzuführen, erstellen wir eine neue Instanz des LRS (das Ziel-LRS) und führen dann einen Statement-Forwarding-Prozess (kurz gesagt, Lesen aus dem Quell-LRS und Schreiben an das Ziel-LRS unter Verwendung der Standard-API, wie sie durch die Spezifikation definiert ist) von Anfang an mit Zeitstempel als Abfrageparameter durch, wobei das Live-LRS (das auch das Quell-LRS ist) die Kunden wie gewohnt bedient, während der gesamten Migration beibehalten wird. Nach erfolgreicher Migration wechseln wir einfach, welcher LRS im Load Balancer verwendet wird, und schon kann es losgehen.
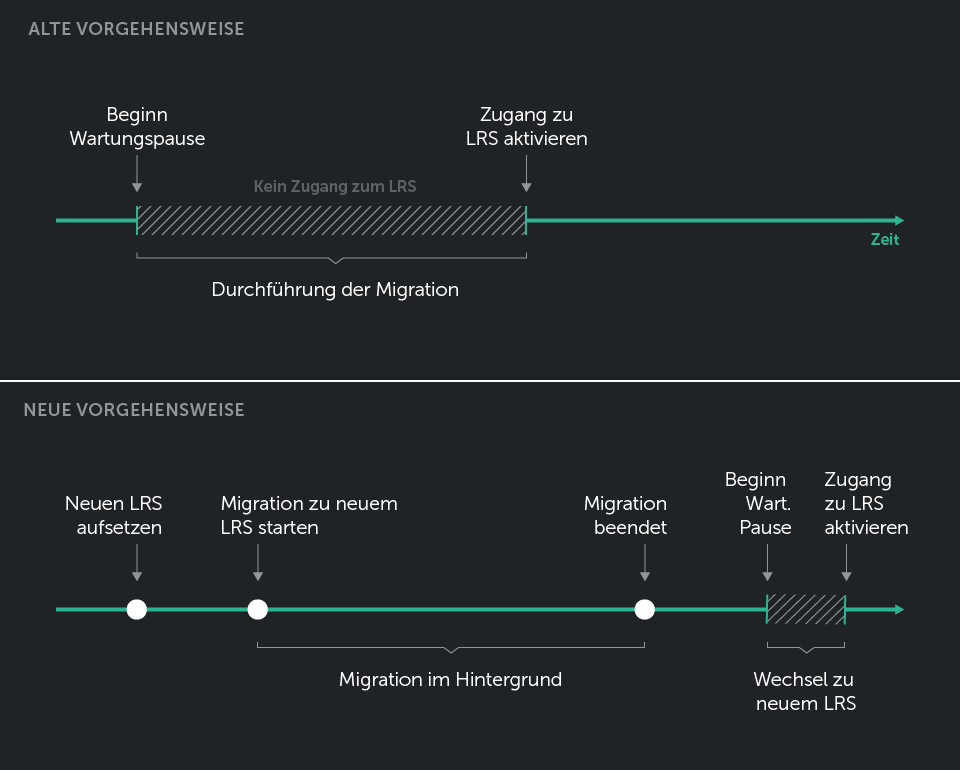
Dies dauert etwas länger im Vergleich zum geraden Ansatz der Migration, hat aber den Bedarf an Wartungspausen sowie die Menge an Fehlern für unsere Kunden und Endanwender stark reduziert – wenn wir jetzt bei der Migration scheitern, haben wir keinen Einfluss auf das Live-System. Wir beheben einfach das Problem und starten den Prozess von vorne.
Dimensionierung der LRS-Umgebung
Ein weiterer Aspekt von LRS im Betrieb ist, dass es in der Lage sein sollte, in kurzer Zeit eine anständige Anzahl von Statements zu erfassen. Lassen Sie mich Ihnen ein Beispiel für die Größe der LRS-Umgebung zeigen, das wir kürzlich für einen unserer Kunden durchgeführt haben.
Aufgrund der Art der Lernverarbeitung hat dieser Kunde einen wöchentlichen Anstieg der Benutzeraktivität, wobei die schlimmste Spitze während einer bestimmten Stunde pro Woche auftritt. Die Anzahl der in dieser Stunde erzeugten Anweisungen liegt bei etwa 35.000, was etwa 10 Anweisungen pro Sekunde entspricht.
Um zukünftiges Wachstum zu antizipieren, haben wir unsere Tests mit 100 Statements pro Sekunde als Ziel durchgeführt, und als Ergebnis haben wir unsere Umgebung so dimensioniert, dass drei Instanzen von LRS (eine ist redundant für Hochverfügbarkeit) hinter dem Load Balancer vorhanden sind, wobei jeder Knoten von LRS auf 2 CPU und 3 GB RAM läuft.
Wir hatten eine 100-prozentige Serviceverfügbarkeit innerhalb des 24-Stunden-Lasttests, wobei sich die LRSs jederzeit im normalen Betriebsmodus befanden und die Server nicht überlastet wurden. Einfache Mathematik führt zu 8,6 Millionen Statements an einem Tag mit unserem Testaufbau. Und wie ich bereits erwähnt habe, hatten wir kürzlich ein weiteres Beispiel für die LRS-Leistung in der Produktion mit (“nur”) 2 Millionen erfassten Anweisungen in zwei Tagen (ja, in diesem Fall gab es viel leistungsfähigere Server in der Produktion, also ein No-Brainer für unseren LRS 🙂 ).
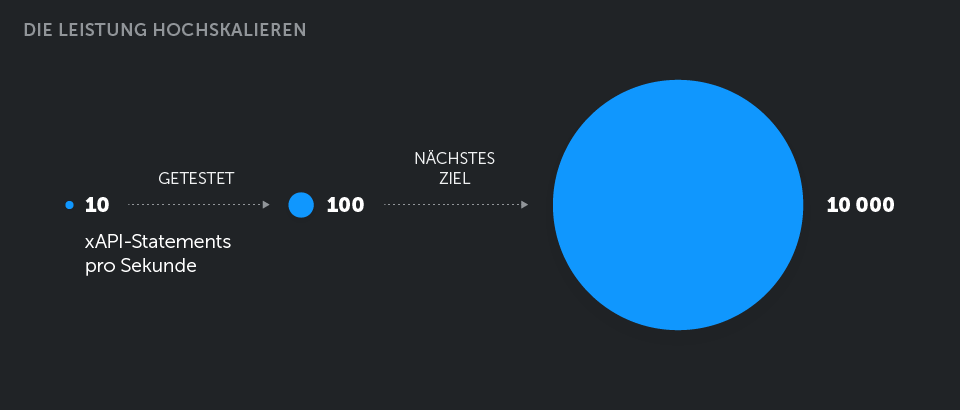
Wir arbeiten nun an der Fähigkeit, 100.000 gleichzeitige Benutzer zu verarbeiten, was etwa 10.000 Anweisungen pro Sekunde entspricht – fast 500 GB JSON-Daten, die an einem einzigen Tag erfasst werden. Wir entwickeln Speicher für unseren LRS mit Cassandra NoSQL, um mit einer solchen Belastung umgehen zu können.
Flexibilität ist ein Vorteil und ein Nachteil
Neben dem Performance-Aspekt gibt es noch einen weiteren Aspekt der Arbeit mit xAPI – im Mittelpunkt der xAPI-Spezifikation steht die Notwendigkeit, aus den Aktivitäten, die an vielen verschiedenen Orten stattfinden, Bedeutung zu gewinnen. Sie müssen wissen, wonach Sie suchen, und Sie müssen in der Lage sein, Daten zu interpretieren, die in Form von xAPI-Anweisungen übergeben werden.
Die xAPI-Spezifikation ist auf Flexibilität ausgelegt und ermöglicht eine große Freiheit bei der Struktur der Anweisungen, wenn es um Details geht. Diese Flexibilität ist ein Vorteil und Nachteil zugleich.
Wir sahen uns dem als Nachteil gegenüber, sobald wir begannen, Lernmaterialien von externen Content-Authoring-Tools wie Articulate Storyline zu verwenden, die xAPI-Anweisungen erzeugten.
Storyline ist ein sehr mächtiges Werkzeug zum Erstellen von interaktiven Lernmaterialien, aber um ehrlich zu sein, waren ihre ersten Experimente mit xAPI bei weitem nicht perfekt, und zu diesem Zeitpunkt war Valamis bereits auf xAPI angewiesen, um den Fortschritt der Lernenden zu verfolgen.
Meistens hatten wir bei älteren Versionen von Storyline Probleme damit, dass der Lernfortschritt der Benutzer in Valamis nicht richtig verfolgt wurde, wobei das System manchmal nicht einmal die Lektionen als bestanden kennzeichnete, selbst wenn der Lernende tatsächlich einen guten Job gemacht und alle Quizfragen erledigt hatte.
Sie haben wahrscheinlich schon von xAPI-Profilen gehört, was die Methode ist, mit der sich verschiedene Systeme darauf einigen können, wie sie die Flexibilität von xAPI nutzen können und welche Bedeutung die Anweisungen haben werden, aber in Wirklichkeit ist die Umsetzung noch nicht da. Es war ein Trial-and-Error-Vorgang, die aussagekräftigen Elemente aus der Folge von Statements zu finden, die von externen Lernpaketen generiert wurden.
Glücklicherweise gibt es auch eine gemeinsame “Quelle der Wahrheit”, auf die Sie sich in diesem Fall verlassen können – SCORM Cloud von Rustici Software ist ein guter Litmus-Test für das Lernpaket, wenn Sie sich nicht sicher sind, ob das Problem in Ihrem System oder im Paket liegt.
Was kommt als nächstes?
Also, was haben wir auf unserer bisherigen fünfjährigen Reise gelernt? Erstens, dass die Einführung von xAPI und der Aufbau eines neuen LRS einen erheblichen Aufwand und wichtige technische Entscheidungen erfordern würde, um mit einer ständig wachsenden Datenmenge Schritt zu halten. Darüber hinaus würde es noch mehr Aufwand und noch wichtigere Lösungen erfordern, um die Daten zu verstehen und darüber hinaus Analysen bereitzustellen.
Wenn Sie auf dem Weg zum Aufbau eines LRS sind, denken Sie von Anfang an daran, dass Sie migrieren müssen. Definieren Sie Ihre Migrationsstrategie und bauen Sie sie in den Kern Ihres LRS ein.
Auch Ihr LRS sollte die Skalierbarkeit von Anfang an berücksichtigen. Denken Sie daran, dass ein LRS eine Vielzahl von Daten enthält und dass diese Menge schneller wächst als die Benutzerzahl Ihres Produkts.
Und last, but not least, denken Sie daran, wie Sie Ihre Daten von dem Punkt an verstehen können, an dem Sie xAPI-Fähigkeiten in Ihr Produkt oder Ihre Integrationen einführen. xAPI ist flexibel, wenn es um den Inhalt der Daten geht, die Sie an das LRS senden. Aber einmal gespeichert, ist es dauerhaft dort, und Sie können nicht weiter beeinflussen, was dort ist und was die Bedeutung der xAPI-Anweisung zum Zeitpunkt des Sendens war.


