xAPI & Valamis LRS – five years in production: what we have learned
In 2014 we implemented our own LRS and started to generate our first xAPI statements. What have we learnt on the journey so far?


The origins of Experience API (or xAPI) date back to 2010, when ADL initiated a research project, the Tin Can Project, completed by Rustici Software. That project resulted in the Tin Can API specification, which later became the xAPI specification. Version 1.0.0 of xAPI was released on April 27, 2013.
There was a lot of interest and excitement in the market toward these new technologies, and we were no different.
Valamis’s product development team was closely following the evolution of xAPI, and in 2014 we implemented our own Learning Record Store (LRS) and started to generate our first xAPI statements to record learners’ progress within our Learning Experience Platform (LXP).
From thousands to millions of statements captured
Let me clarify first these central terms used in this blog.
xAPI is a standard (or specification) that allows the tracking, storing, and sharing of the learning experience of the user across platforms and in multiple contexts.
A Learning Record Store (LRS) is a data store system that serves as a repository for learning records collected from connected systems.
Production usage of Valamis LRS started in autumn 2014—since then, a lot has changed, and we have learned a lot as well.
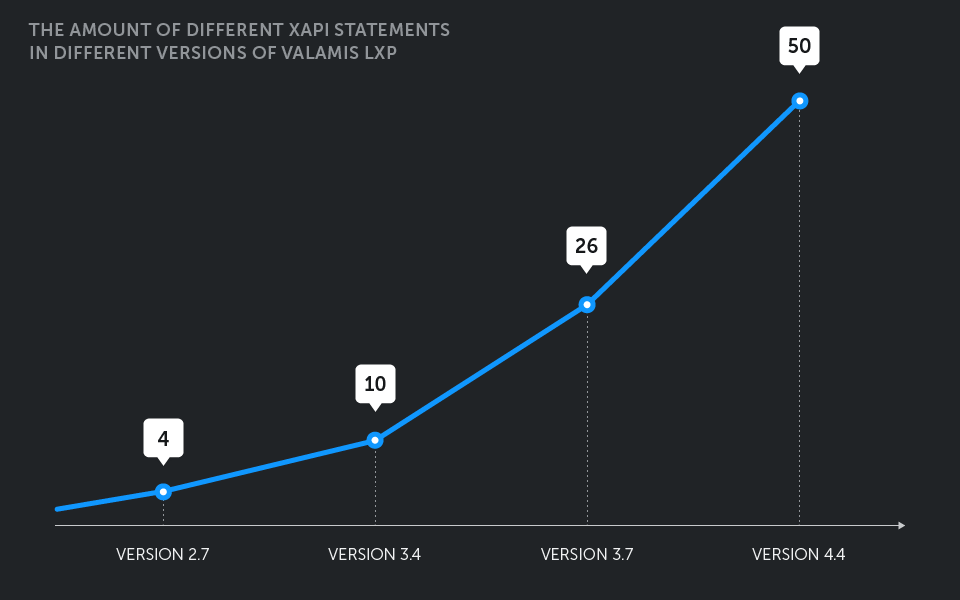
The number of different events captured by xAPI statements in Valamis LXP has increased more than 10-fold, from just 4 initially to 50 in the latest version, with more coming in each new release.
The daily generation rate for some of our customers’ environments (see picture below) is in the tens of thousands of statements, with a recent peak performance of two million captured over just two days. These drastically increasing numbers are a positive sign, but behind them was a lot of sweat and tears, long days, and a significant team effort.
Data. Lots of data
The first and most important lesson for us was that our LRS would not just contain data—it would contain a huge, incomprehensible pile of it.
From the very start, we faced the issue of getting meaning out of the data we collected.
Soon, we started to think that xAPI wasn’t actually designed for reporting and that our naive approach of building reports by querying LRS directly wasn’t the wisest choice.
Over a couple of years, we made many iterative improvements to be able to process xAPI statements on the fly and to present real-time analytics based on the data collected, but we are far from being satisfied with current status.
That is why we are working on a NoSQL solution that will give us the ability to get real-time analytics with the help of Spark.
Challenges with migration
Another implication of the amount of data, in addition to analytics performance, is the difficulty of iterative evolution, namely migration.
Each improvement we make to the data model and storage requires existing data to be migrated to the new model, and our naive approach of doing these database migrations directly resulted in long (and usually unexpected) maintenance breaks.
We had to rethink our approach to the migration completely.
Ultimately, we opted for a simpler strategy. Instead of migrating the live LRS, we set up a new instance—the target LRS. We then initiated a statement-forwarding process.
In essence, this involved reading from the source LRS and writing to the target LRS using the standard API, as outlined in the specification.
From the very start, we used timestamps as a query parameter. Throughout the entire migration, the live LRS, which also served as the source, continued to serve customers as usual.
After successful migration we just switch which LRS will be used in the load balancer, and we are good to go.
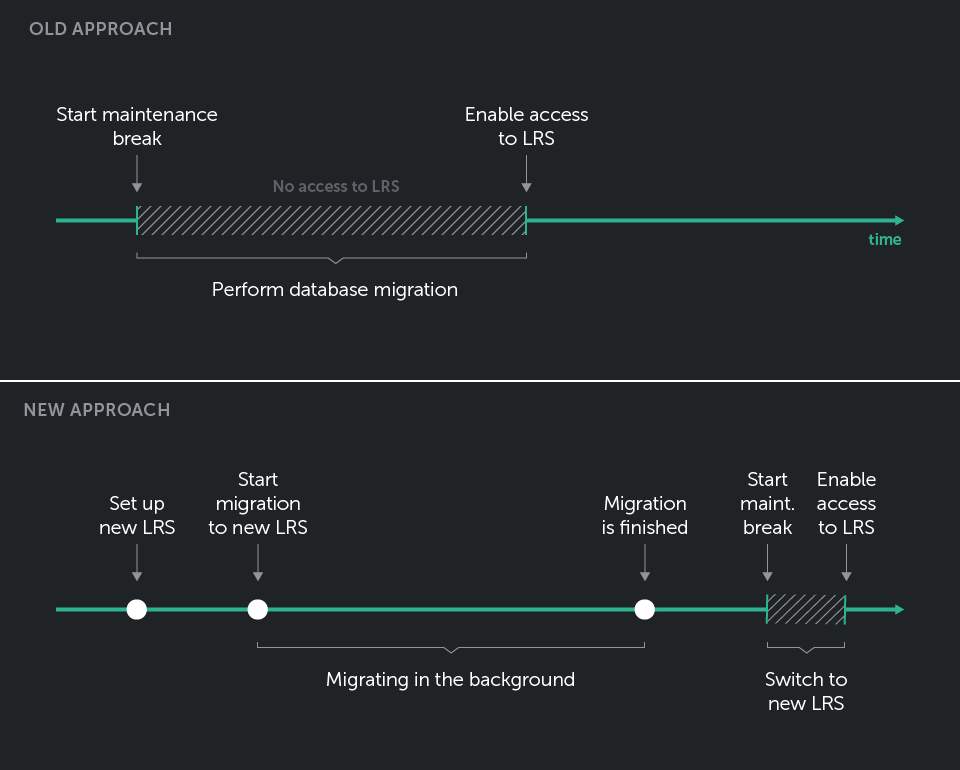
This takes a bit longer in comparison to the straight approach of migrating in place, but it has greatly reduced the need for maintenance breaks as well as that of things going wrong for our customers and end-users – if we fail in migration now, we don’t affect the live system. We just fix the problem and start the process again from the very beginning.
Sizing the LRS environment
Another aspect of LRS in operation is that it should be capable of capturing a decent amount of statements in a short period of time.
Let me show you one example of the LRS environment sizing that we did for one of our clients recently.
Due to the nature of their learning processing, this client has a weekly spike of user activity, with the worst peak happening during one particular hour every week. The amount of statements generated during that hour is around 35,000, which is roughly 10 statements per second.
To anticipate future growth, we conducted our testing with 100 statements per second as a target, and as a result we sized our environment to have three instances of LRS (one is redundant for high availability) behind the load balancer, with each node of LRS running on 2 CPU and 3 GB RAM.
We had 100 percent service availability within the 24-hour load test, with LRS’s being in a normal operation mode at all times and without the servers going crazy.
Simple math results in 8.6 million statements in one day with our testing setup.
And as I already mentioned, we recently had another example of LRS performance in production with (“only”) 2 million statements had captured in two days (yes, there were much more powerful servers in production in this case, so a no-brainer for our LRS 🙂 ).
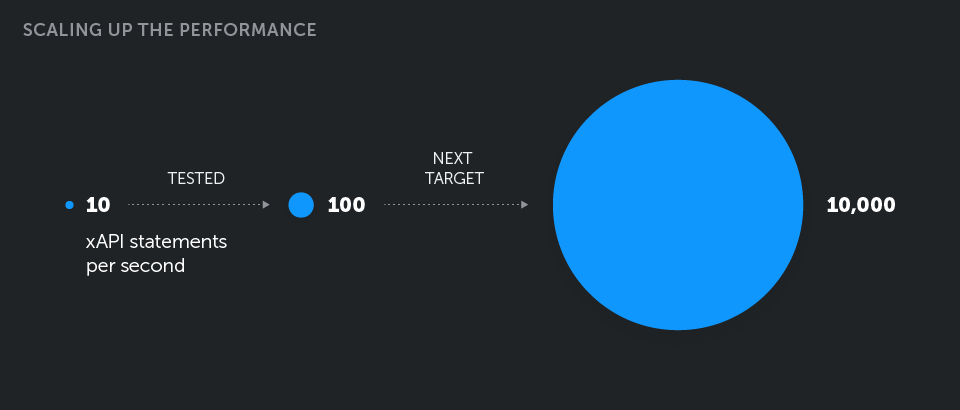
We are now working on the capability to handle 100,000 simultaneous users, which equates to about 10,000 statements per second—almost 500 GB of JSON data captured in a single day. We are developing storage for our LRS using Cassandra NoSQL to be able to cope with such a load.
Flexibility is an advantage and a disadvantage
In addition to the performance aspect, there is also another angle of working with xAPI—at the very core of the xAPI specification is the need to get meaning out of the activities happening in many different places.
You need to know what you are looking for, and you need to be able to interpret data passed in the form of xAPI statements.
The xAPI specification is built with flexibility in mind, and it allows for great freedom with the structure of the statements when it comes down to the details.
This flexibility is an advantage and a disadvantage at the same time.
We faced it as a disadvantage as soon as we started to use learning materials from external content-authoring tools like Articulate Storyline, which were producing xAPI statements.
The Storyline is a very powerful tool for building interactive learning materials, but to be honest, their first experiments with xAPI were far from perfect, and at that time Valamis was already dependent on xAPI for tracking learners’ progress.
More often than not, with older versions of Storyline, we had issues with users’ learning progress not being tracked properly in Valamis, with the system sometimes not even marking lessons as being passed, even if the learner had actually done a great job and cleared all the quizzes.
You have probably heard about xAPI Profiles, which are the method for different systems to agree on how to use xAPI’s flexibility and what meaning the statements will have, but in reality, the adoption is not yet there. It was a trial-and-error path of finding the meaningful pieces from the sequence of statements, generated by external learning packages.
Luckily, there is also a common “source of truth” that you can rely on in this case—SCORM Cloud from Rustici Software is a good litmus test for the learning package when you are in doubt as to whether the problem is in your system or in the package.
What’s up next?
So, what have we learned on our five-year journey so far?
First of all, that adoption of xAPI and the building of a new LRS would require considerable effort and nontrivial technical decisions to keep up with a constantly growing quantity of data.
Further, making sense of the data and providing analytics on top of it would require even more effort and even less trivial solutions.
If you are on your way to building an LRS, keep in mind from the very beginning that you need to migrate. Define your migration strategy and build it into the core of your LRS.
Your LRS should also be taking scalability into account from the very beginning. Remember that an LRS will contain a LOT of data, and that quantity will be growing faster than your product’s user base.
And last, but not least, think of how to make sense of your data from the point where you introduce xAPI capabilities into your product or your integrations.
xAPI is flexible when it comes to the content of the data you send into the LRS. But once stored, it is permanently there, and you can’t further affect what is there vs. what the xAPI statement’s meaning was at the time that it was sent.


