Why do we spend all that time searching for information at work?
One enterprise can own millions of videos, presentations, documents and other forms of information from different data sources. But is it easy to find what you are looking for from that mass of data?


One enterprise can own millions of videos, presentations, documents and other forms of information from different data sources. But is it easy to find what you are looking for from that mass of data?
And what about structuring and categorizing the data? If your company has 10,000 hours of video, it’s not really realistic for people to carefully go through and categorize that amount of content. The videos are searchable only by the titles and short descriptions, and the actual video content remains out of reach for the search engine.
According to a McKinsey report, employees spend 1.8 hours every day searching and gathering information. On average, that’s 9.3 hours per week!
Current enterprise search solutions lack efficiency and end up wasting hours of precious time.
Finding information that matters doesn’t have to be like finding a needle in a haystack
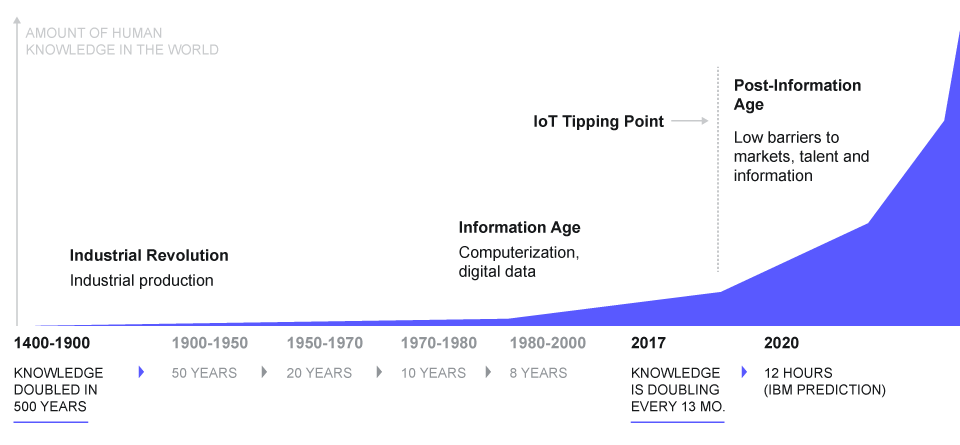
Figure 1: Knowledge Doubling Curve by Buckminster Fuller.
As the amount of data keeps multiplying (figure 1), it is impossible for a human being to read and tag everything. We need more efficient ways to access and structurize the information. Luckily, we live in a world with Artificial Intelligence (AI). AI helps us to process Big Data and access the information that would otherwise be lost.
Gartner points out in their “Improve Search to Deliver Insight” analysis (refreshed Oct 2018, Published May 2017) that “At their zenith of performance, search engines surface relevant content when, where and how employees need it. Minimizing the effort required to achieve this maximizes the value to the business.”
At Valamis, we developed an AI solution within our Learning Experience Platform (LXP) that enables better access to information. It is not only a powerful enterprise search, but it includes a recommendation engine and analyst tools that can make the most out of a corporation’s content.
In this blog, we will dive into the benefits of the solution, explain the technology behind it, and show how our customers are using it.
Intelligent knowledge discovery releases the knowledge
Intelligent Knowledge Discovery is a solution that helps you to easily gain access to all the information your organization has, in addition to external content and other resources. In Intelligent Knowledge Discovery we linked together several IBM Watson applications to create a comprehensive and precise knowledge management system.
The AI-based solution uses Natural Language Processing (NLP), Visual Recognition, and Machine Learning to go through and analyze all of your content. It combines human language and visuals into a form that a machine can understand, interpret, process, analyze and then manipulate.
It recognizes moments in your videos, tags your content, and categorizes it by theme or concept. It will read all of your documents and watch all your videos so that you don’t need to. And the next time you search for something, it will point you to the exact moment in the video where the information you are looking for is found.
If your company has 1000 hours of video, according to our estimate, it would take 2000 hours from a human worker to watch the video, capture and tag all the moments in the video.
Watson can do the same work in under 10 hours.
And perhaps later you would like to change your categorization, tag the moments even more precisely, or find the connections between two different themes in all your video material. It would perhaps take the human worker another 2000 hours to do this all.
IBM Watson technology can do it in less than 10 hours. Watson can be taught to be more precise in processing the content, to find the most valuable information, and it can do it in a fraction of the time it would take a human worker.
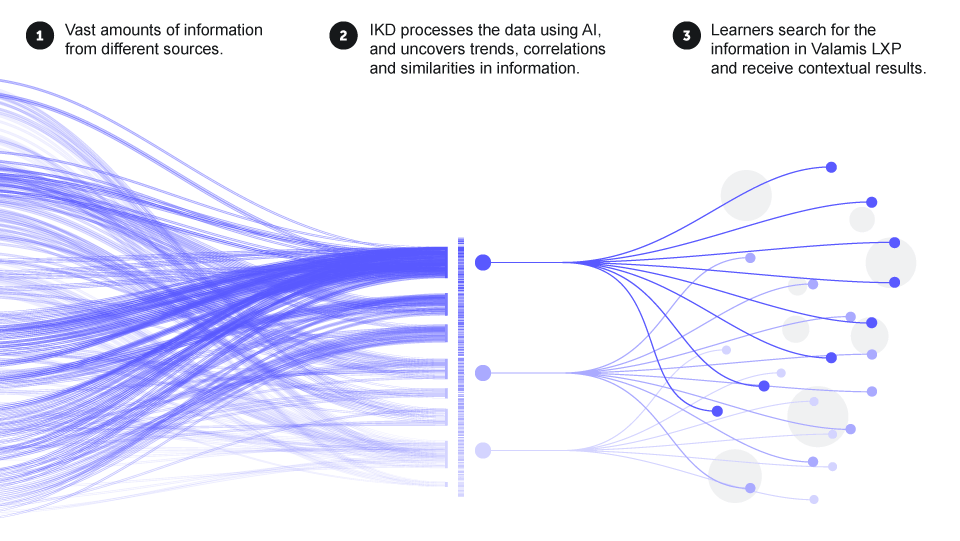
Figure 2.
Intelligent Knowledge Discovery is not only a search; it can make intelligent recommendations. It can also identify trends, similarities and connections between different videos and different parts of a text and other content. It then can compare the connections with what the learners are currently working on so content can be highly targeted and relevant based on the individual learner’s needs.
Cognitive search understands what your documents and files are about
In this section, we delve deeper into the technology behind Watson and Intelligent Knowledge Discovery. In IKD, Cognitive Search and AI solutions play a major part in processing real-world human language.
Cognitive Search uses natural language processing (NLP) and Machine Learning to capture, process, understand, structurize and reform data from multiple databases. NLP refers to the ability of computers to understand and communicate with humans in their natural language. NLP is present in our everyday life without us even noticing. Picture yourself texting on your phone or writing a document on your computer and you make an error. That’s NLP recognizing the error and suggesting an alternative.
In the case of Intelligent Knowledge Discovery, a process could be something like this:
You have a presentation in 30 minutes and are experiencing anxiety about it. You want to find out fast how you can relieve your presentation anxiety and stress. You remember that your company’s learning platform has a few lessons on public speaking, but you wish to find some quick tips to survive.
Before Intelligent Knowledge Discovery existed, you would need to try to search keywords in order to find a course, document or video.
With IKD’s Cognitive Search, you will be able to go through the database much faster, since NLP has already analyzed both the text and video material. It will find the answer for you and link you to the specific spot in the text or the video. For example, NLP can find the three best tips and a 5-minute exercise, leaving you with plenty of time to prepare.
This is all possible because the combination of NLP and Machine Learning Cognitive Search can:
- Understand any form of data you have linked to it.
- Process Big Data.
- Be embedded in your Learning Experience Platform, and anyone can use it.
Natural language processing in a nutshell
Natural Language Processing is about using tools, techniques and algorithms to make a computer read and write in natural language. In order to realize how that works, we need to go through different NLP problems and aspects to see how NLP works. NLP can be broken down into three core parts (figure 3):
- Converting information into natural language
- Understanding natural language
- Generating natural language

Figure 3.
These 3 core parts can be split into a NLP pipeline, a workflow of several sequential steps.
Converting information into natural language
The first step of the pipeline is to collect natural language-based data in the form of videos, pictures and speech and transform the words into text format.
This step involves configuring speech recognition and optical character recognition tools that have had major performance improvements in recent years.
Sometimes more advanced tools are needed. For example, another tool is necessary in order to recognize a speaker from another video.
Natural language understanding enables the contextualization
With data in a text format, we need Natural Language Understanding (NLU). It is a vital part of successful NLP. NLU focuses on converting text into a structured form that machines can understand and act upon.
Understanding of a text is a simple task for a human but a difficult task for machines-understanding English is a hard thing. And marginal, more complex languages like Finnish or Swedish are even harder!
NLU is not as simple as training a machine to understand vocabulary or counting keyword frequencies. It includes several steps of breaking the text down parts and teaching a machine.
Text pre-processing is essentially cleaning and formatting the text. There are a lot of idiosyncrasies that need to be dealt with like: mispronunciation, colloquialisms, abbreviations and compound words. This makes it possible, for example, for the machine to understand the comments and feedback that your employees have made about a course, and it makes them available to the search as new, peer-to-peer information that was not originally included in your learning material.
After pre-processing, the next step in NLU is structural analysis. In any natural language, there is a general structure and syntax on how singular words combine into phrases, clauses and sentences. Common steps in structural analysis involve splitting text into sentences and then into separate words. These words are then tagged with their part of speech and the grammatical structure of a sentence is then analyzed via parsing algorithms. This results in the machine’s understanding of the structure and syntax, so, for instance, it can recognize the difference between verbs and nouns, which is very beneficial for many other steps of NLP like text classification via Machine Learning.
Then finally, the semantic analysis gives NLU the capability to understand the meaning and context. The most familiar use cases of semantic analysis are automatic keyword detection (tagging) and an understanding of the emotion denoted in the text (sentiment analysis). However, a more sophisticated semantic analysis is a continuously evolving area that aims at being able to understand both the person and the content. Here’s an example:
You search content for the keyword: “Tiger” and results are:
- An animal
- A zodiac
- A film
- A beer
- A tank
- An Apple operating system
So as a result, a more sophisticated semantic analysis is able to give you the context that you are interested in and smoother user experience.
Machine Learning recognizes the hidden structures
The last area of NLU is Machine Learning. NLP developers can train models via supervised or unsupervised learning. Supervised learning means text classification and it requires a lot of labeled data. Unsupervised learning or clustering is another area of applied Machine Learning that can be used to recognize hidden structures, topics or similar documents. With Machine Learning you focus on the issue as a classification problem instead of understanding the meaning. Machine Learning is fast and it doesn’t care about the intricacies of natural language as long as there is enough training data. Machine Learning is great at learning certain limited insights such as overall sentiment.
In reality, structural and semantic analysis is time-consuming. Sustaining a collection of relevant patterns for natural language is difficult, as natural language is constantly evolving. Both traditional NLP components and Machine Learning is needed. In Intelligent Knowledge Discovery, we have integrated both NLP and Machine Learning. All of these techniques and steps roll into a set of applications that can be integrated into Cognitive Search, business processes and a chatbot. All of this can be included in Valamis’ Intelligent Knowledge Discovery. Traditional NLP provides a basic layer of analysis and contextualization. Machine Learning models use the outputs of the basic layer and offer a higher layer of analysis to recognize structures, topics and intent.
How to retain the knowledge in a large organization: a case example
Our customer, a large organization from the US, is facing a problem when its longtime employees begin to retire. Huge amounts of valuable knowledge is in danger of disappearing as people leave the organization. To retain as much information as possible, the organization decided to use Intelligent Knowledge Discovery.
They decided to record their employees speaking on a video, to save their knowledge. Hours and hours of video material combined with documents and presentations collected over tens of years equate to a massive chunk of valuable knowledge.
To make this knowledge accessible, the Intelligent Knowledge Discovery solution structures the information, and the cognitive search helps any user to find the information they are looking for.
Meet Jack
Jack is a longtime employee in the organization, and about to retire. Jack has a lot of siloed knowledge that has never been written down.
Since Jack does not have time to prepare courses or presentations, he has decided to share his knowledge by answering the questions the younger employees want to ask him. The younger employees vote for the best questions and every week Jack turns his webcam on and broadcasts a webinar, answering the questions and discussing the topics.
After the webinar, Intelligent Knowledge Discovery processes the video, compares it to other content and sets the theme and tags, then indexes it, and makes it readily available for anyone within the organization to search. Jack’s knowledge is now saved and easy to access for the future employees of the organization.
Federated search brings even more information available
Intelligent Knowledge Discovery can also access information via your integrations. IKD exposes the search engine index from external sources like OpenSesame, LinkedIn Learning, and edX. It can also reach all internal documents beyond the learning platform from sources like Google Drive, OneDrive, Dropbox and Slack.
From a user perspective, Intelligent Knowledge Discovery utilizes the power of multiple search engines in one search. This will save time for an L&D team because now all of the material doesn’t have to be produced in-house nor does the material need to be added to the company’s Learning Experience Platform. Despite not adding the material to the learning platform, user engagement and other learning analytics can still be accessed via xAPI statements, resulting in an all encompassing learning ecosystem.
More than an enterprise search
Once Intelligent Knowledge Discovery has processed all of your content by utilizing its Machine Learning capabilities, it can analyze what the learners are searching for, and what concepts seem to be the most interesting.
Intelligent Knowledge Discovery can help you to recognize if there is a gap in the learning materials. This way you will be able to start the process to create new, and more relevant learning materials for your employees to support their daily work. Or in some cases, you can even spot an emerging crisis within a project.
When IKD helps to spot the skill gaps and learning needs as soon as they emerge, you will be able to be more proactive, and you can cut costs.
Another possible usage for Intelligent Knowledge Discovery is to help you better recognize the experts within your organization so you can connect the right people to the right teams. As you find out who searches what in your system, and who learns what, you will be able to find subject matter experts and target job tasks more precisely. This can also help in finding untapped potential in your employees.
The better knowledge management
“Not only does the LXP need intelligent methods to recommend content […], but they can also be used to recommend third-party articles, find people who are experts, and potentially index documents, videos, and other digital assets. In a sense, they are content management, knowledge management, and learning systems all in one – which is why the market is growing so quickly.”
– Josh Bersin, industry analyst, Learning Experience Platform (LXP) Market Grows Up: Now Too Big To Ignore
According to industry analyst Josh Bersin, there is a growing demand for the feature we have described in this blog. Intelligent Knowledge Discovery as a part of organizational learning and our Learning Experience Platform is here to stay and keeps evolving. The technology is easy to use, enabling the leap for better knowledge management within organizations.
From the learning point of view, Intelligent Knowledge Discovery enrichens both the content and the data collected from the learners. The data and information available multiplies as all the information available can be evaluated and tagged by the machine.
The data available from consuming the information multiplies as well, enabling further development in the content analysis. The relation between work and learning activities can be made clear, as personal learning becomes more specific.
The qualitative feedback from the search will be able to see beyond good headings, also known as clickbait. This means that the learners will not be automatically directed to the video or article that has been clicked the most, but the one that actually has the most suitable content.
Currently, old school search engines ask users, “Was this search result useful to you?” In the future, companies will have a tool that finds the answer to the question on its own by combining the search tool and learning analytics and tracking learner activity. ‘Did the user click any of the search results? How much time did they spend consuming the materials? Did the interaction or learning activity result in a change in behavior?’
Based on the learning data, the system will be able to analyze the quality of the search result and content. It will be able to deduce if the learner did not find what they were looking for, and alter the future search results based on that.
As technology advances, the human brain can and will be — and is currently being merged with computers and Artificial Intelligence. Or the peer-to-peer information could be transferred from thoughts to thoughts with a bit of help from a machine.
We may not live in the Matrix just yet, but maybe in the future, the knowledge needed within our work will be embedded in our heads before we even think of searching for it.