What is Experience API (xAPI)?
The article reveals what xAPI is. Its benefits, how it works, history and examples. Comparison of xAPI vs. SCORM vs. AICC and why choose xAPI over them.


Online training programs are a great way to pass knowledge from one person to another.
They are scalable, can be built to be evergreen, and, best of all, metrics can be used alongside these courses to inform and evaluate both the courses and the progress of the users.
One of the key questions online learning providers ask themselves is whether or not their training program is effective.
There are several specifications that can be used to measure the effectiveness of an eLearning environment. The big three are SCORM, AICC and Experience API (xAPI).
xAPI is the newest of these specifications and considered to be the industry standard. As we take an in-depth look at xAPI, we will also take a look at the differences between these three specifications.
Contents:
- What is xAPI?
- Project Tin Can: the story of xAPI creation
- Benefits of Experience API (xAPI)
- How xAPI works
- Examples of xAPI in action
- cmi5 and xAPI
- xAPI vs SCORM: What is the difference?
- Why choose xAPI over SCORM?
- xAPI vs AICC: What is the difference?
- Why choose xAPI over AICC?
What is Experience API (xAPI)?
xAPI is a standard that allows the tracking, storing, and sharing of the learning experience of the user across platforms and in multiple contexts.
Learning does not only occur on the learning management system, and so data should come from more sources than just the LMS.
xAPI allows creators and managers of online learning programs to better understand how users are learning, both online and offline. This ability to track the learning of the user across multiple scenarios and platforms means that the data is more complete.
Project Tin Can: the story of xAPI creation

xAPI was developed by the US Department of Defense-funded Advanced Distributed Learning (ADL) in conjunction with Rustici Software and a large community of SCORM users who suggested improvements.
When the project was started, it was named ‘Project Tin Can’ in homage to the two-way nature of the collaboration between the ADL and the community.
The idea was to come up with the next gen SCORM, a system that had increasingly failed to keep up with the changes in technology and learning habits of users.
The project fused a decade of collective learning experiences with a decade of technological advancement. Although the project was renamed Experience API, it is sometimes still referred to as Tin Can API.
xAPI allows creators and managers to take a closer look at how users are interacting with online learning programs.
According to Wikipedia “Experience API (xAPI) is an e-learning software specification that allows learning content and learning systems to speak to each other in a manner that records and tracks all types of learning experiences.”
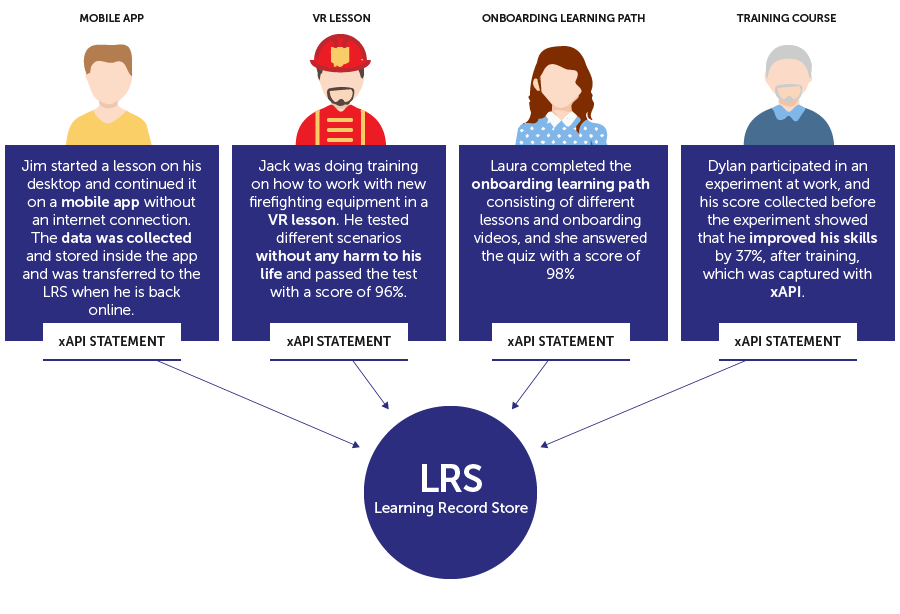
The records generated by xAPI are activity statements, collected in an ‘I did this’ (also known as an actor-verb-direct object) statement, alongside a variety of contextual data that can be chosen by the creator of the course.
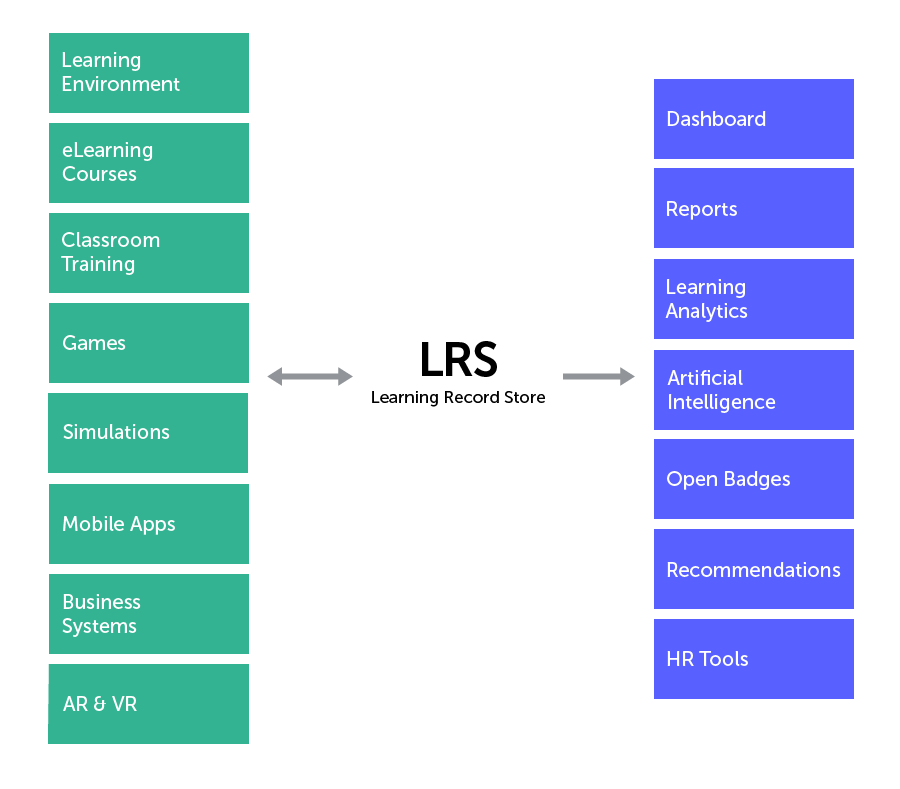
These activity statements are then collected from the various sources chosen and stored in a Learning Record Store (LRS). The LRS is similar to the SCORM database in an LMS – a location in which users can find all of the data that they need, ready to be interpreted.
Benefits of Experience API (xAPI)
1. xAPI allows you to better understand your data
Data capture
xAPI allows the capture of data from a vast array of sources, both online and offline.
In previous systems, the data capture was limited to the LMS, which only gives a narrow, partial view of how learners are engaging with the content.
With xAPI, a big difference is the ability to track learning on mobile devices – where roughly 40% of learning happens.
Learners can interact with material on one device and pick up where they left off on another device later on.
Not only that, offline learning can be tracked, such as real-world performance and team-based eLearning.
Integration
The ability of xAPI to capture data from many different sources and integrate it into one learning record means that you can get a holistic view of learning activity.
A complete picture of learning can be created, showing where strengths and weaknesses lie.
This allows the identification of necessary learning interventions, as well as tracking individual successes that can lead to teachable moments.
Data transfer
Data stored within the LRS can be easily retrieved and transferred not only within the LRS but also to other reporting systems.
This allows for the easy sharing of data within your organization.

Use learning data to accelerate change
Understand learning data and receive a practical tool to help apply this knowledge in your company.
Download workbook2. xAPI gives your organization the ability to connect learning and performance
xAPI is able to track games and simulations, real-world performance, e-learning on mobile and desktop devices, learning plans, and goals.
The data collected allows you to connect systems on a high level and analyze data, which in turn allows for the discovery of patterns that would otherwise be invisible.
Your organization will become more able to respond quickly, implement learning interventions before problems develop, and understand trends within the company.
xAPI helps with talent management and development
In order to know who within your organization or company would be best situated for a role, you can use xAPI.
Linking learning and development to performance and talent management means that rising stars can be found early and developed within the company, setting them up for success within their role and keeping their talent within the organization.
xAPI provides better insights about your customers
Every organization can benefit from getting more insight into what their audience thinks or feels. xAPI can help this process in multiple ways.
Using xAPI, an organization can track the user’s actions across multiple devices and environments, through apps, portals, websites, phones or PCs – you can see from start to finish how customers interact with your product, tool or software.
Another example would be an audit of user interactions with a set of tutorials. If you have a product and have developed a series of training tutorials to help onboard new users, you would like to know which of them work the best.
Using xAPI, you can collect statements of interactions, activities, and results, which are then transferred to your LRS.
You can then analyze the data for patterns of usage. For example, you could pinpoint areas where more users exit the app or have some issues, at the same time you can determine after what tutorials users interaction improves. Based on such insights, developers can test alternatives to problem areas.
This will overall allow for increased satisfaction with the product.
3. xAPI keeps your data secure and structured
It serves as a security method allowing for the exchange of information between the Learning Record Store and trusted sources.
This data is important to your company, and will often contain information that is sensitive.
xAPI also helps in the structuring and definition of statement, state, learner, activity, and objects, which are the means by which experiences are conveyed by a learner activity provider.
4. xAPI helps improve your learning assets
Experience API gives organizations powerful tools for analyzing the impact of learning and organization goals.
The analytics clearly show which parts of the learning program need to be improved for future learners, which are working well, and areas in which the company should focus on.

Compliance ≠ complicated
Get compliance training right, every time. Just what your team needs, straight from our LMS.
Our compliance solutionsHow xAPI works
In order to understand how it works, it is helpful to define certain terminologies.
Terminologies
Learning Activity: This is a unit of instruction, experience, or performance that is tracked.
Learning Activity Provider (AP): Any system or thing that is communicating with the LRS to record information about a learning activity that is occurring within the context of the AP. This can be something within the content of a learning management system, but could also be a simulator, a forklift, or a social media network, among many other things.
Statement: A piece of information consisting of <actor (learner)> <verb> <direct object>, with <result> (for example: John watched training video 2 in full), in <context> to track an aspect of a learning experience. A set of several statements may be used to track complete details about a learning experience.
Learning Record Store (LRS): A system that stores statements. The xAPI is dependent on an LRS to function correctly. An LRS can store a wide range of learning experiences, be it real-world activities, mobile applications usage, or job performance. The data can be shared with other systems and provide analytical information so the learning experience can be adapted accordingly.
How does xAPI work?
- The instructional designer chooses how many (or how few) statements their learning activity should generate. This can be one or several hundred, or anything in between.
- xAPI statements are usually written in JSON (Javascript Object Notation Language). This language is similar to XML. The experiences are recorded in the form of simple actor-verb-object statements.
- More detailed statements can also be generated for learning activity results and context activities. Documents and files can be attached. These statements are gathered by APs and sent to the LRS, and can also be sent by the LRS to other systems.
- The user is not limited to any specific device and doesn’t have to be connected to the web all the time. In offline mode, statements are collected and stored on the device or within the environment, which are then sent to the LRS when an online connection is restored.
- The Learning Record Store (LRS) receives, stores, and structures data in the form of statements, ready for it to be interpreted and reviewed. An LRS is essential when you are working with Experience API. It works as a central store that sends and retrieves data about the learning that has taken place.
Examples of xAPI in action
1. xAPI and VR
An exciting technology that can very effectively be used with xAPI is virtual reality.
As the tech becomes more usable, cost-effective and popular, companies are quickly seeing how it can be paired with xAPI to more effectively track learning.
An example of effective use of xAPI and VR would be training sessions where multiple people in locations across the globe can work together to learn a new skill. With expert guidance paired with VR and xAPI, users can learn how to pilot a plane, repair a vehicle, even how to work in space, all without any danger to their lives and much more cost-effectively than in-real training.
VR training increases retention and results in a shorter learning path, allowing employees to be trained much faster than traditional methods. Training is achieved quickly and effectively, without costly and time-consuming travel, all within an environment where metrics can be tracked and evaluated.
Interactions within a VR environment can be personalized to fit the exact needs of the company, ranging from quizzes to decision-making tags to conditional scenarios and beyond. The ease with which a company could build custom renditions of likely scenarios means that the training goes beyond simply providing information and the trainee passively receiving it.
With xAPI, this learning can be tracked from the first moment of training, providing a complete picture of how this person learns and interact, allowing for the early triggering of learning interventions if necessary.
Use learning data to accelerate change
Understand learning data and receive a practical tool to help apply this knowledge in your company.
Download workbookNot only can employees be trained, but visitors and other non-staff can go through VR training at sites where security is a high priority. In areas where safety protocols must be followed, all visitors go through an employee onboarding process. To ensure that they complete and understand the training, VR can be used, with xAPI collecting and sending the data to verify completion.
2. xAPI in a healthcare environment
xAPI helps in connecting training data to healthcare KPIs to save lives. When it comes to responding to a heart attack, the speed is vital as it determines the difference between life and death.
Using xAPI, a large healthcare provider MedStar Health, created a blended learning program that allowed them to approach the learning experience from several different angles.
Using the provider’s existing LMS, in-person simulations through xAPI apps and a mobile defibrillator app, they began gathering information such as course completion data from the LMS, usage data from the defibrillator app, and in-person data from simulations.
This data then allowed for precise targeting of performance management, including looking at what factors led to success for their employees.
3. xAPI in a multinational, Fortune 100 environment
A global company Caterpillar Inc. (CAT), involved in the design, engineering, manufacture and sales of engines, machinery, insurance and financial products realized the need to update their learning and development systems, making them more learner-focused, rather than compliance-focused.
To do so, they created a blended system, joining instructor-led training with digital content and using xAPI to inform the various ways that content is created and delivered within this system.
Within various channels, including a dedicated YouTube account and an app for in-house content creation, digital insights can be easily collected, giving a full view of how learners interact with the content, including how they navigate through, where they click, and which activities are popular with users.
AI systems can prompt users to interact with content when it is needed, rather than when the user actively looks for it. Curating and delivering content on a daily basis reinforces learning activities, as well as develops a learning mindset within the workforce.
As the system has been built to tie learning metrics to KPIs, analytics can be studied and key insights can be gleaned from the data. Using those insights, the company can improve L&D, target specific metrics, and continuously develop learning within their workforce.
4. xAPI in a telecommunications environment
Introducing xAPI into an L&D environment, especially one in a global company such as Verizon, can present a challenge.
There are hundreds of moving parts, stakeholders, and departments that must work together to roll out a new system. At one telecommunications giant, the process has been incremental, but even in the early stages, has delivered results good enough that the entire company is in the process of switching to an xAPI-based system.
Seeing a need for the data, analytics and personalized learning experiences offered with xAPI, one L&D director pioneered the switch from an onboarding program consisting of a PowerPoint presentation to one that was fully online, accessible via mobile devices, and was able to provide insights to the LMS.
Building on the success of that, they have expanded the data that they are collecting, exploring new types of content, analyzing the consumption habits of users to better tailor content for them, and making content more accessible for users.
5. xAPI in a restaurant environment
In order to test if xAPI could help their business, a global restaurant brand – Yum! Brands, did a test with one restaurant, to see if there was a correlation between employee training and store performance.
The test was done with three key data sources: Completion of employee training materials, usage of the store team portal, and store performance metrics collected in an internal system.
Blending those data sources with xAPI allowed for a full analysis, delivering meaningful insights about the use of training materials versus store performance. After the test, the brand has put in motion plans to utilize xAPI throughout their stores.
6. xAPI in a sales environment
For companies with a sales force that is mostly out in the field, xAPI can bring a variety of tools to their fingertips while helping the organization monitor a workforce that interacts on multiple devices across many contexts.
Behr Paint Company, with a sales force that spends 95% of their time at retail locations, needed a powerful system that was decentralized, flexible, able to organize and deliver content and could provide analysis to better help the content team deliver what the sales team needed.
Using an app for delivery and iPads as the main access point, this organization created three main functions.
- One function allows the reps to teach customers about the product, mainly in the form of videos searchable by tags or by barcode scans that can bring up training material related to that product.
- A second function stores sales presentations, consumer reports, and other non-customer facing items.
- The third function is for the sales reps themselves to interact with learning materials, which can then earn them rewards if they are consistently and actively engaging with the content.
The app uses a dashboard that showcases the most popular materials over the last 30 days, informed by xAPI content interactions. While allowing reps to see what materials their peers are finding useful, this also allows the content and L&D teams to see how reps are interacting with the content, what is popular, and what is not.
The data from xAPI in a sales context can be helpful in understanding the success or failure of reps. Organizations can look at how a successful rep interacts with apps, training material and other tools and then use that data to try and replicate success for other reps.
xAPI helps to understand success by putting together performance data from your CRM, engagement with scenario-based training and assessments, data from call listening and coaching sessions. If one rep is having issues, for example, losing three sales in a row, a learning intervention can be triggered by the system.
By using data to trigger and personalize what happens next, you can spot and address potential issues early on.
7. xAPI in talent management
An organization can use xAPI to drive talent management and development.
Examining the skills and attributes that successful employees demonstrate, management can map out what other employees need to do to become similarly successful. Using that information, a simulated environment can be built which will deliver assessment data via xAPI to inform and support talent management efforts.
This gives the ability to see which team members will be successful and in which roles they will thrive.
Successful talent management means that employees are supported early and often, and xAPI can highlight the best ways to do so. This means that talent is kept in the organization, recruiting costs are lowered, and organizational knowledge is kept more effectively.
cmi5 and xAPI
cmi5 brings several aspects of increased functionality, including statement definitions for specific events.
cmi5 statements fall into two categories:
‘cmi5 defined’‘cmi5 allowed’
Both of these types of statements track learning activity, with cmi5 defined statements tracking pass/fail, content completion, duration and score, capturing data points for existing functions.
cmi5 allowed statements are almost open-ended, allowing a high level of flexibility in data capture with regard to specific events.
Content created with cmi5 can include many modules, or blocks, of content, can have several different launches of the same content, can include different launch modes, and is more secure, thanks to a specific cmi5 ‘handshake’ credentialing process that happens upon launch.
xAPI vs SCORM: What is the difference?
SCORM was a system that helped change the face of eLearning, allowing content to move seamlessly between different LMS and giving the ability to track some data.
As eLearning changed, however, a new system was needed. New devices for learning had appeared, more was known about the learning habits of users, and it was time for a new system to be developed.
When comparing xAPI vs. SCORM, the main difference is that xAPI allows the tracking of learning activity from multiple contexts online and offline, not just on the LMS.
xAPI is fast becoming the new industry standard, challenging SCORM for dominance in the e-learning sphere.
- As it is a newer technology, it has the ability to integrate mobile and offline learning in a way that SCORM simply cannot.
- Using xAPI allows creators to track, evaluate, personalize and improve the learning experience of users in a much more responsive and nuanced manner.
- Where SCORM only tracks desktop LMS activity, xAPI pulls data from multiple sources both on and offline into one place, a learning record store (LRS). This translates to a more complete data set that demonstrates where and how learning is happening, and, crucially, where it is not. Learning experiences and on-the-job performance can be linked.
For example, high performing employees can be studied and that data can be used to reverse engineer success. By studying the ways in which those employees succeed, other employees can be trained to do the same, and interventions can be triggered within this system to catch issues before they become serious.
xAPI came as a result of the shortcomings of SCORM. Take a look at the significant differences between xAPI vs. SCORM.
| Feature | xAPI | SCORM |
|---|---|---|
| Track completion | ||
| Track time | ||
| Track pass/fail | ||
| Report a single score | ||
| Report multiple scores | ||
| Detailed test results | ||
| Solid security | ||
| No LMS required | ||
| No internet browser required | ||
| Keep complete control over your content | ||
| No cross domain limitation | ||
| Use mobile apps for learning | ||
| Platform transition | ||
| Track serious games | ||
| Track simulations | ||
| Track informal learning | ||
| Track real world performances | ||
| Track office learning | ||
| Track interactive learning | ||
| Track adaptive learning | ||
| Track blended learning | ||
| Track long term learning | ||
| Track team based learning |
Download the free brochure xAPI vs. SCORM vs. AICC: What is the Difference?
Why choose xAPI over SCORM?
- xAPI is a newer standard that integrates the technology that learners are likely to use. An estimated 56% of learners use mobile devices to access course materials, and this data would not be collected with SCORM.
- The improved integration means that the data set is larger, more nuanced and more informative. Insights are gleaned more easily and improvements can be made due to enhanced understanding of learner behavior.
More companies are switching to xAPI and this trend shows no sign of stopping. As data-driven learning continues to be a growing sector, xAPI will be a very useful tool for e-learning creators.
Choosing xAPI allows you to benefit from a technology that is evolving over time, which SCORM is not.
xAPI vs AICC: What is the difference?
AICC is an acronym for Aviation Industry Computer-Based Training Committee.
According to Wikipedia, “AICC specifications are usually designed to be general purpose (not necessarily aviation specific) so that learning technology vendors can spread their costs across multiple markets and thus provide products needed by the aviation industry at a lower cost. This strategy has resulted in AICC specifications having broad acceptance and relevance to non-aviation and aviation users alike”.
it was established in 1988 by Boeing, Airbus and McDonnell Douglas to standardize the training materials and technology used to train airline workers.
AICC is considered ancient in terms of technology, outdated, has limited functionality and lacks progress tracking abilities.
Unlike in xAPI, in AICC the data structure is complicated. Multiple functions are necessary to remove information that is stored on the single text string returned by the server. Issues such as scripting across browsers, common in AICC, are not present in xAPI.
Experience API is not yet as supported as AICC is, although it is gaining notable adopters quickly. The fact remains that xAPI is not as widely supported as SCORM or AICC.
That could limit your options in the near-term when it comes to authoring tools and LMS. You will find further elaboration on the differences between experience API and AICC in the table below.
Why choose xAPI over AICC?
As AICC was created in the 80’s, it can’t keep up with the changes in technology that have happened in the last 30 years.
Although it remains a great option for organizations who need high security, as AICC supports secure HTTPS data transfers, AICC does not offer the same benefits as xAPI.
- xAPI is the newest specification, offering access to the most cutting edge technology. As more organizations move to xAPI, they are leaving behind older systems.
- xAPI offers the ability to track learning online, offline, and in multiple contexts, which is not available with AICC.
- xAPI offers a simple process to remove data from the string returned by the server, making it a quick and error-free process to analyze data.
xAPI gives creators more flexibility, the ability to create advanced tracking, and as AICC grows ever older, it is going to become more obsolete as more users make the switch to xAPI.
Conclusion
xAPI is opening up new opportunities for not only tracking learning experiences but also extending learning into everyday life. When learning data can be connected with data about performance behaviors and actual business results, organizations can see the connection between their learning efforts and organizational improvements.
And that is what it’s really about. We are able to move past relying on completions as a key metric and instead can focus on revenue, costs, safety, satisfaction, delivering on the mission and capabilities.
Experience API is the only standard that can support the future of eLearning. Not only is it able to support more complex and varied learning scenarios that can better engage worker and audience, but it also gives trainers the detailed interaction data they need to improve learning experience over time.


